Việc sử dụng các mô hình ngôn ngữ lớn (LLM) dựa trên đám mây chưa bao giờ khiến tôi hoàn toàn thoải mái. Hầu hết chúng yêu cầu gửi dữ liệu của bạn đến các máy chủ từ xa, điều này đặt ra những lo ngại rõ ràng về quyền riêng tư. Thêm vào đó, nhiều công cụ AI bị khóa sau các gói đăng ký đắt đỏ, và bạn có rất ít quyền kiểm soát cách chúng hoạt động.
Với tốc độ cải thiện nhanh chóng của các mô hình cục bộ, tôi muốn xem liệu việc chạy LLM cục bộ của riêng mình cuối cùng đã trở nên khả thi hay chưa. Có một số lý do để thử tự host LLM, vì vậy tôi đã thử sức và thực sự khá kinh ngạc với những gì mình đạt được.
Ollama: Đơn Giản Hóa Việc Thiết Lập LLM Cục Bộ
Dễ dàng ngay cả với người mới tự host
Đối với thiết lập của mình, tôi đã sử dụng Ollama làm công cụ cốt lõi để chạy các mô hình ngôn ngữ. Nếu bạn chưa từng nghe nói về nó, Ollama là một framework nhẹ được thiết kế để giúp việc chạy các mô hình ngôn ngữ lớn cục bộ trở nên dễ tiếp cận hơn nhiều. Nó xử lý toàn bộ quá trình, từ tải xuống các tệp mô hình đến thiết lập môi trường chạy và quản lý tài nguyên phần cứng.
Bạn có thể chạy các mô hình chỉ với vài lệnh terminal mà không cần tự mình xử lý tất cả cấu hình backend thường đi kèm với các LLM cục bộ. Ollama hoạt động hoàn toàn trên máy của bạn, vì vậy các mô hình và dữ liệu vẫn ở trong máy. Nó hỗ trợ hầu hết các mô hình mã nguồn mở như DeepSeek, LLaMA và nhiều mô hình khác, thậm chí bạn có thể tải mô hình của riêng mình nếu muốn. Ollama cũng tự động xử lý các tối ưu hóa để đảm bảo các mô hình chạy hiệu quả dựa trên phần cứng của bạn.
Mặc dù Ollama không được đóng gói (containerized) theo mặc định, tôi đã chạy toàn bộ hệ thống bên trong Docker để giữ mọi thứ cô lập và dễ quản lý hơn. Điều đó cũng giúp thiết lập trở nên linh hoạt và tránh mọi xung đột với các phụ thuộc khác trên hệ thống của tôi.
 Giao diện người dùng Ollama hiển thị các mô hình ngôn ngữ lớn (LLM) có sẵn để tải và chạy cục bộ
Giao diện người dùng Ollama hiển thị các mô hình ngôn ngữ lớn (LLM) có sẵn để tải và chạy cục bộ
Về giao diện người dùng, tôi đã ghép nối Ollama với Open WebUI. Đây là một giao diện web mã nguồn mở kết nối trực tiếp với API của Ollama, cung cấp một giao diện kiểu trò chuyện (chat-style) gọn gàng để tương tác với các mô hình của bạn. Tôi đã triển khai hệ thống này bằng Ngrok để có thể truy cập từ xa một cách an toàn, trong khi Open WebUI cũng xử lý xác thực cơ bản để giữ mọi thứ được bảo mật.
Trải Nghiệm Thật Sự Bất Ngờ Khi Chạy LLM Trên Phần Cứng Cá Nhân
AI cục bộ mượt mà hơn mong đợi
Bước đầu tiên là chọn một mô hình phù hợp, và tôi đã chọn mô hình DeepSeek R1 với 7 tỷ tham số (7B parameter). Tôi đang chạy mọi thứ trên một chiếc MacBook Air với chip M1 và 16GB bộ nhớ hợp nhất (unified memory). Đây chắc chắn không phải là một cỗ máy được xây dựng cho khối lượng công việc AI nặng, nhưng tôi đã ngạc nhiên về khả năng xử lý của nó.
Miễn là tôi để LLM chạy một mình, nó hoạt động hoàn toàn ổn định. Chỉ khi tôi cố gắng thực hiện các tác vụ khác trên máy Mac trong khi mô hình đang chạy, nó mới bắt đầu chậm lại.
Thành thật mà nói, tôi đã nghĩ rằng toàn bộ quá trình sẽ là một thảm họa. Chạy LLM là một trong những tác vụ đòi hỏi nhiều tài nguyên nhất mà bạn có thể thực hiện trên phần cứng tiêu dùng. Nhưng vì tôi chỉ sử dụng mô hình 7B, nó vẫn có thể quản lý được ngay cả trên chiếc MacBook của tôi.
Nói một cách đơn giản, 7B có nghĩa là mô hình có khoảng bảy tỷ tham số. Bạn có thể coi các tham số như những cài đặt hoặc hướng dẫn nhỏ bên trong mô hình giúp nó hiểu ngôn ngữ, tạo ra phản hồi hoặc giải quyết vấn đề. Mô hình càng có nhiều tham số thì khả năng của nó càng tiên tiến, nhưng điều đó cũng có nghĩa là bạn cần phần cứng mạnh hơn để chạy nó. Bảy tỷ nghe có vẻ nhiều, nhưng nó được coi là một trong những mô hình nhẹ hơn, hiệu quả hơn mà vẫn hoạt động tốt cho các tác vụ hữu ích.
Ngay cả với những giới hạn đó, mô hình vẫn xử lý các yêu cầu đơn giản mà không gặp vấn đề gì. Tôi đã sử dụng nó để gỡ lỗi các cơ sở mã cơ bản trong các chuyến bay và cho các tác vụ ngoại tuyến nhanh chóng. Nếu bạn có phần cứng mạnh hơn, bạn có thể vượt xa 7B và chạy các mô hình lớn hơn như 32B hoặc thậm chí 70B tham số, có thể xử lý các yêu cầu phức tạp hơn với khả năng suy luận và độ chính xác tốt hơn.
Nhưng ngay cả với một thiết lập khiêm tốn, việc chạy một LLM cục bộ hóa ra lại khả thi một cách đáng ngạc nhiên.
Chưa Thay Thế Hoàn Toàn ChatGPT: Những Giới Hạn Cần Chú Ý
Vẫn có lúc cần đến sức mạnh đám mây
Mặc dù tôi rất thích thú khi chạy một LLM cục bộ, nhưng nó vẫn chưa thay thế hoàn toàn các công cụ như ChatGPT đối với tôi. Tôi chủ yếu sử dụng thiết lập cục bộ cho các tác vụ nhẹ hơn hoặc khi tôi không có quyền truy cập internet, ví dụ như khi đi du lịch. Đối với các bản sửa lỗi mã nhanh, bản nháp hoặc các yêu cầu đơn giản, mô hình 7B hoạt động đủ tốt và thành thật mà nói, nó còn hơn cả đủ cho hầu hết các tác vụ liên quan đến LLM của tôi. Tuy nhiên, vẫn có những tình huống mà tôi yêu cầu hiệu suất, độ chính xác hoặc chuyên môn bổ sung mà các mô hình dựa trên đám mây cung cấp, và đó là lúc tôi quay lại ChatGPT hoặc các công cụ tương tự.
Ví dụ, tôi đã hỏi DeepSeek R1 về chiếc iPhone đầu tiên, và nó đã đưa ra một câu trả lời sai hài hước. Nó tuyên bố rằng iPhone nguyên bản ra mắt vào năm 1986, điều này rõ ràng là không chính xác, và tôi đã cười rất nhiều khi xem xét những câu hỏi như thế này.
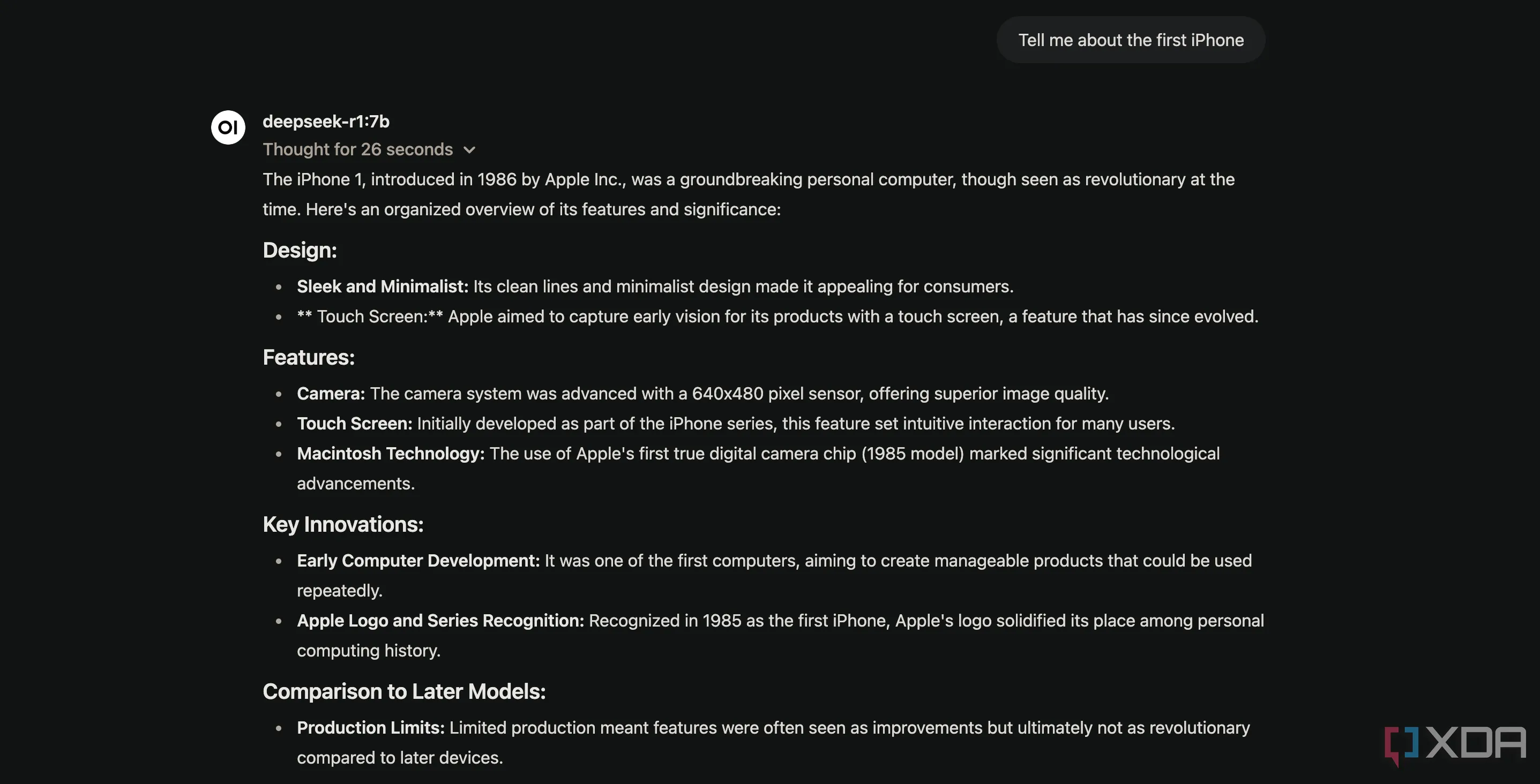 Mô hình DeepSeek-R1 chạy cục bộ trên MacBook Air và đưa ra thông tin sai lệch khi hỏi về iPhone đời đầu
Mô hình DeepSeek-R1 chạy cục bộ trên MacBook Air và đưa ra thông tin sai lệch khi hỏi về iPhone đời đầu
Nếu bạn đang nghĩ đến việc chạy một LLM trên Raspberry Pi hoặc các phần cứng công suất thấp khác, bạn sẽ phải hạ thấp kỳ vọng của mình hơn nữa. Trong những trường hợp đó, bạn có thể sẽ bị giới hạn ở các mô hình nhỏ hơn nhiều với khoảng 1.5 tỷ tham số, chỉ có thể xử lý các truy vấn rất cơ bản.
Các mô hình đám mây như ChatGPT vẫn có lợi thế về khả năng thô. Chúng thường hỗ trợ các tính năng như tìm kiếm web và plugin, và dữ liệu của chúng thường được cập nhật gần đây hơn. Trừ khi bạn có phần cứng mạnh mẽ để chạy các mô hình lớn hơn nhiều cục bộ, việc đạt được trải nghiệm tương đương là chưa thực tế vào thời điểm hiện tại.
Việc tự chạy LLM cục bộ là một bước tiến đáng kinh ngạc trong việc kiểm soát dữ liệu và tối ưu hóa chi phí sử dụng AI. Với các công cụ như Ollama và Open WebUI, quá trình này trở nên dễ tiếp cận hơn bao giờ hết, mang lại trải nghiệm mượt mà ngay cả trên phần cứng khiêm tốn. Mặc dù vẫn còn những giới hạn về khả năng so với các mô hình đám mây như ChatGPT, đặc biệt đối với các tác vụ phức tạp hoặc đòi hỏi kiến thức cập nhật, LLM cục bộ là một giải pháp tuyệt vời cho các nhu cầu cá nhân, bảo mật và khi không có internet.
Nếu bạn đang tìm kiếm một phương án kiểm soát tốt hơn dữ liệu của mình và muốn khám phá tiềm năng của AI cá nhân, việc tự host LLM chắc chắn là một trải nghiệm đáng để thử. Hãy chia sẻ ý kiến hoặc trải nghiệm của bạn về việc chạy LLM cục bộ trong phần bình luận bên dưới nhé!